LLM Routers - The AI Dispatchers You Didn't Know You Needed
AGI is coming - or so they say. But what exactly is AGI? Definitions differ, yet my favorite describes AGI as the ultimate generalist: imagine an AI that possesses the combined expertise of top human specialists across every conceivable field. And that’s the “G” in AGI (artificial general intelligence). Instead of the “jack of all trades, master of none” concept, AGI is the “master of all trades”.
While AGI isn’t here yet, we have many large language models (LLMs) rapidly moving in that direction. However, a closer look at leaderboards such as Chatbot Arena and standard benchmarks reveals something interesting: most AI models aren’t generalists. They are actually specialists.
Most AI models aren’t generalists. They are specialists.
Some excel at real-world coding, others at mathematics, writing, science, research, competitive coding, or questions. Today, there are over 200,000 LLMs open-sourced on Hugging Face. And most are small and focused on specialized tasks.
So if you’re building an AI-powered product designed to handle diverse use cases, choosing just one LLM won’t cut it.
Enter LLM routers - technology that allows you to leverage multiple specialized models, routing each task to the model best suited to handle it. Why settle for one when you can pick exactly the right AI for every task?
Let’s dive deeper into the world of LLM routing and explore how it works.
Understanding LLM Routing
LLM routing operates by evaluating incoming queries and assigning them to the optimal model. Simpler tasks can be handled by smaller, more efficient models. Complex tasks are directed to larger, more capable ones. And specialist tasks can be directed to the best model for the job. This approach ensures that resources are allocated effectively, maintaining high-quality responses without unnecessary expenditure.
Benefits of LLM Routing
- Cost Reduction: By directing simpler queries to smaller models, you can significantly reduce operational costs. For instance, routers can cut inferencing costs by up to 85% by diverting a subset of queries to more efficient models.
- Improved Speed: Smaller models process queries faster, leading to quicker response times for less complex tasks. This enhances user experience by providing timely answers without compromising quality.
- Maintained Accuracy: Complex queries are handled by larger models capable of delivering high-quality responses, ensuring that accuracy is preserved where it matters most. Simpler routers can maintain 90% of the accuracy, while more complex ones can push that closer to 98%.
- User Friendliness: Today’s chatbots require users to do a lot of work and know a lot of technical details (e.g. how to best prompt, what model is the best for my query). Routers allow you to hide that complexity or offer a “choose for me” option. Why force your users to make a choice while newer models are introduced every day? Keep things simple and hide those details behind a router.
- Benefit from Market Innovations. Related to user friendliness, companies that use just one model will be at a big disadvantage since new faster, cheaper, and more powerful models are launched every week. It’s more advantageous to have a router setup, allowing you to more simply swap in new models. Don’t put your eggs in one basket.
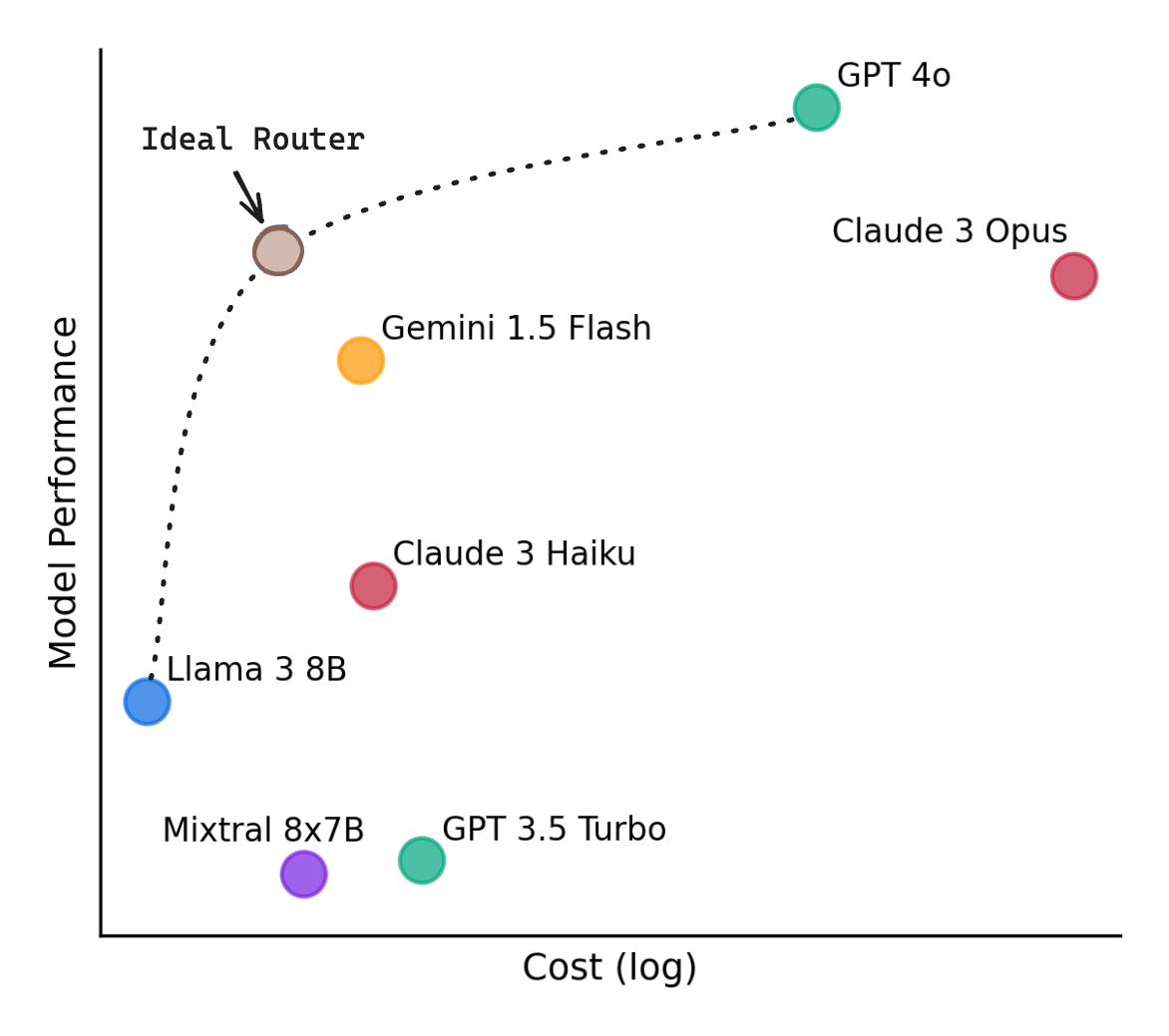
Routers can find a more optimal balance across quality and costs (RouteLLM)
Types of Routers
There’s many ways of introducing routing to your flows, ranging from simple to very complex. Let’s walk through each.
Simple Routing
This is the most basic version introduced in the early RouteLLM paper. Build a router to decide between a smaller LLM (like Llama3 8B, Phi-4-mini, or Claude Haiku) or a larger model (like, GPT 4.5, Claude Sonnet, or Grok 3). Again, the larger state of the art models can do almost anything well, but come at a very steep price.
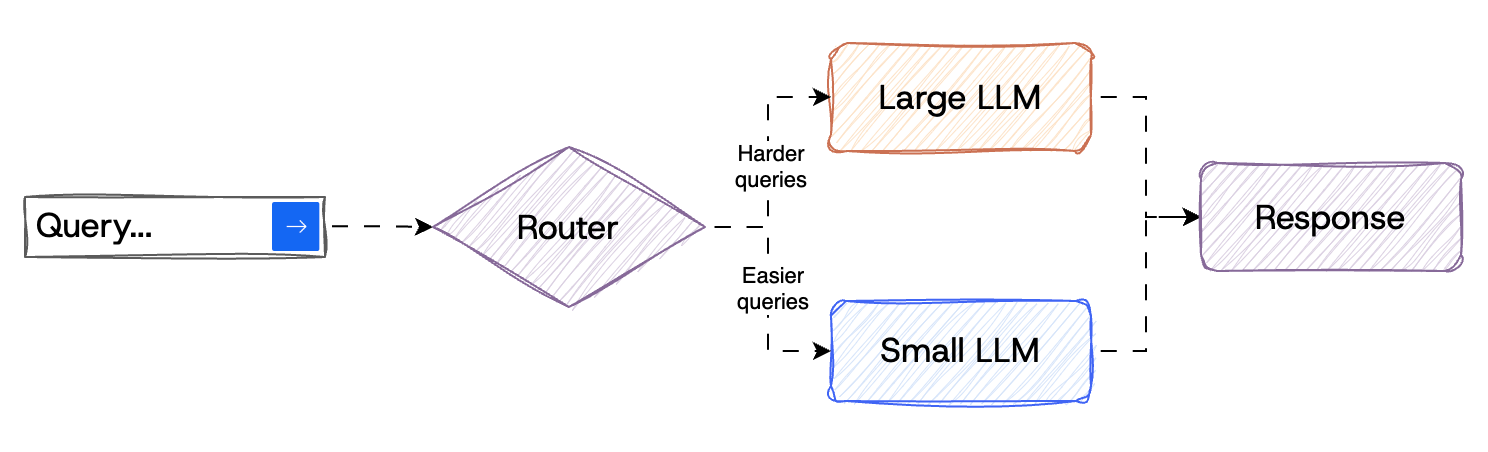
Basic router for simple and complex tasks
Specialist Routing
This method involves training a routing algorithm on benchmark data to predict which model will best handle a given query. By analyzing the strengths and weaknesses of each model, the router can make informed decisions, enhancing both accuracy and cost-efficiency. Hugging Face lists 200,000 LLMs today that are lighter-weight and highly specialized.
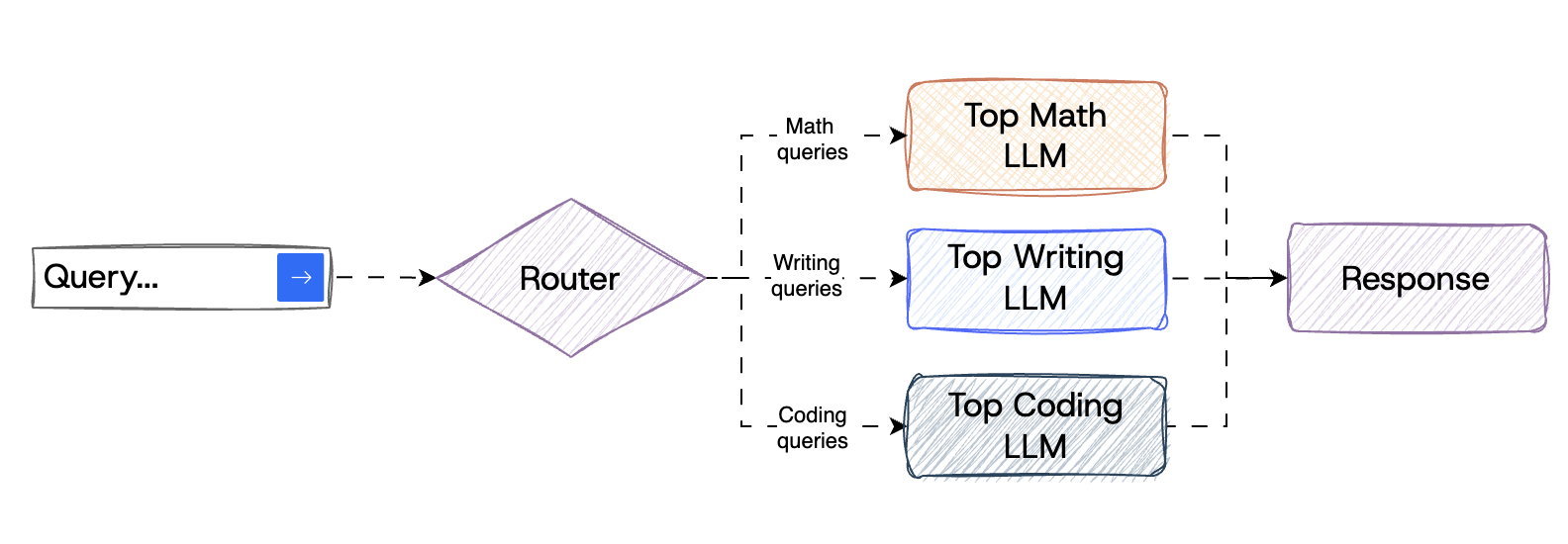
Route to model tuned for specific task
An alternative approach to specialist routing was presented in the Prompt to leaderboard paper. They trained their router using data from Chatbot Arena which has humans decide what answer they prefer between two options. Normally the state of the art (SOTA) models dominate since they are the most capable across all categories. But by leveraging the fact that even the state of the art models differ in their strengths, their approach of routing to the optimal one led to them becoming #1.
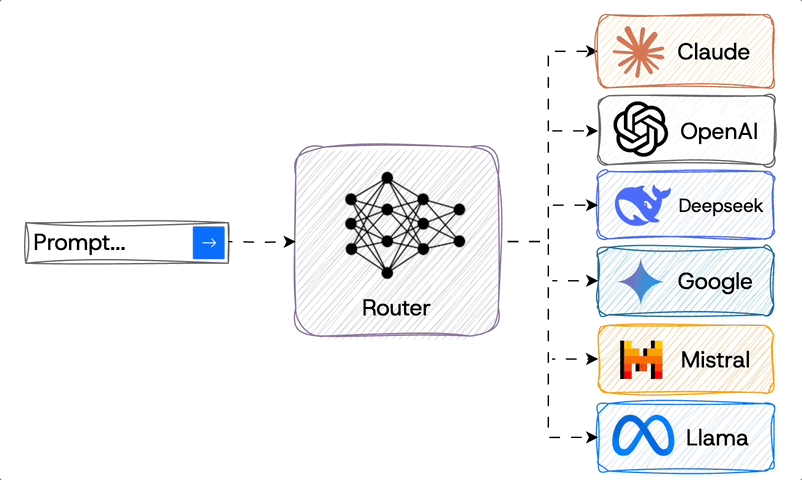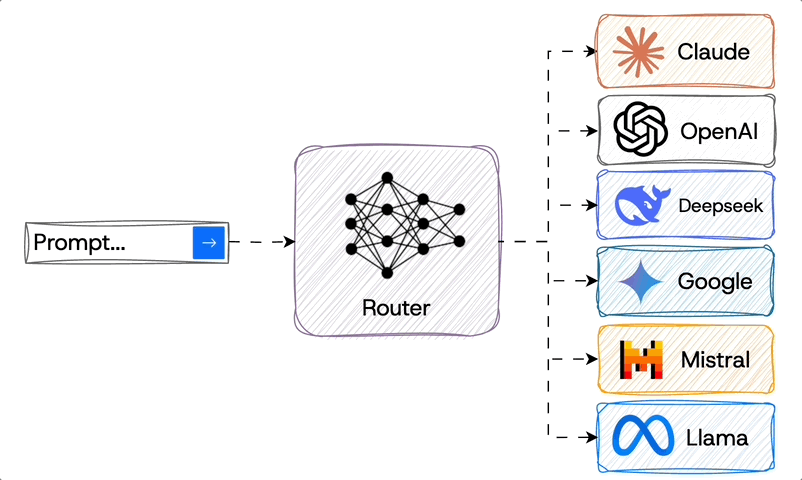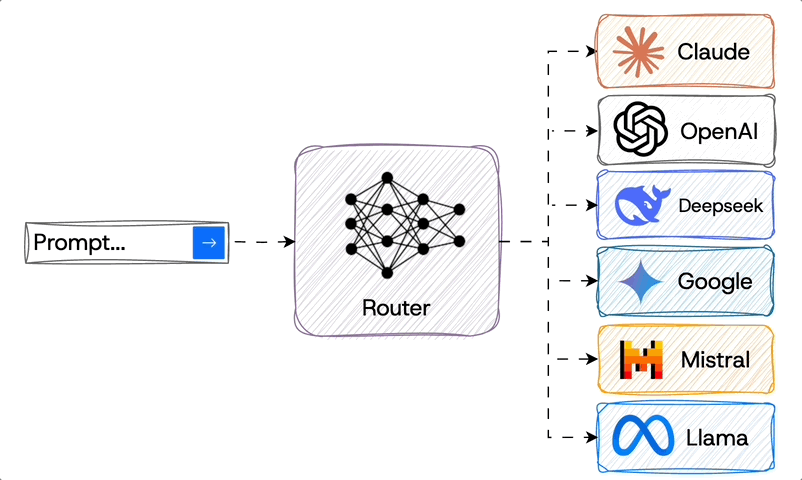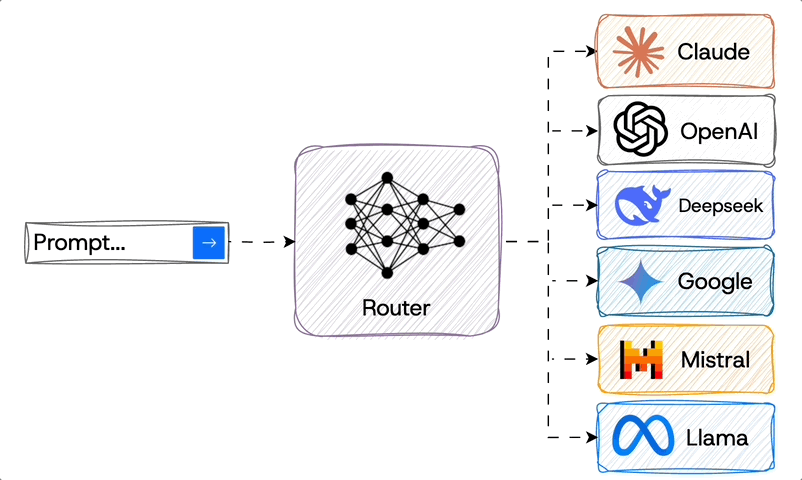
Router to different company LLMs
Local Routing
A variant of simple routing, local routing can take advantage of more and more capable edge devices like your laptop or even mobile phone. With technology like llama.cpp and ollama, running LLMs on your laptop or server has never been easier.
The catch is that only the smallest models can reliably run on this hardware (for now). Google’s Gemma 3n is a great example of how these smaller models are innovating on compute and memory usage. For example, Gemma 3n uses a Matryoshka Transformer (MatFormer architecture) that contains nested, smaller models within a single, larger model.
So with local routing, simply send easier queries to your local models and harder queries to more capable cloud-based LLMs. The router itself can run on the device.
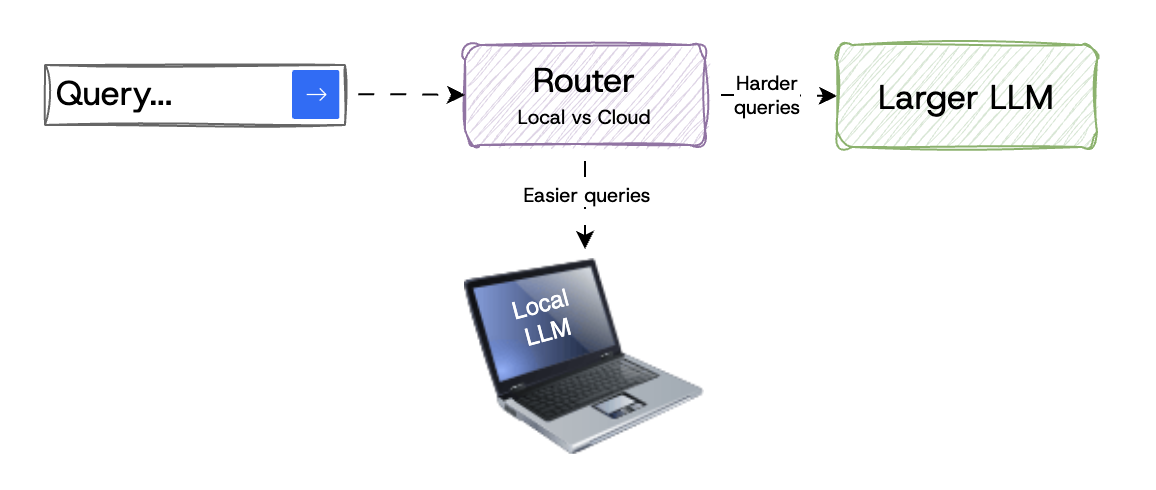
Leverage local compute to handle some tasks locally vs. paying cloud costs
The Hybrid LLM paper showed by training a router to handle easy queries locally, they were able to make 40% fewer calls to more expensive cloud-based LLMs.
Cascading Routing
In this approach, queries are first sent to smaller, less expensive models. If the response quality is insufficient, the query is escalated to more powerful models. This can then be repeated if necessary.
This tiered system ensures that only necessary resources are utilized for complex tasks. Though does come at the cost of latency through wasted compute on harder tasks.
A Unified Approach to Routing and Cascading for LLMs paper introduced an even more advanced version where both cascading and routing is done at each step. This leads to further improvements, cost efficiencies, and helps with overall latency.
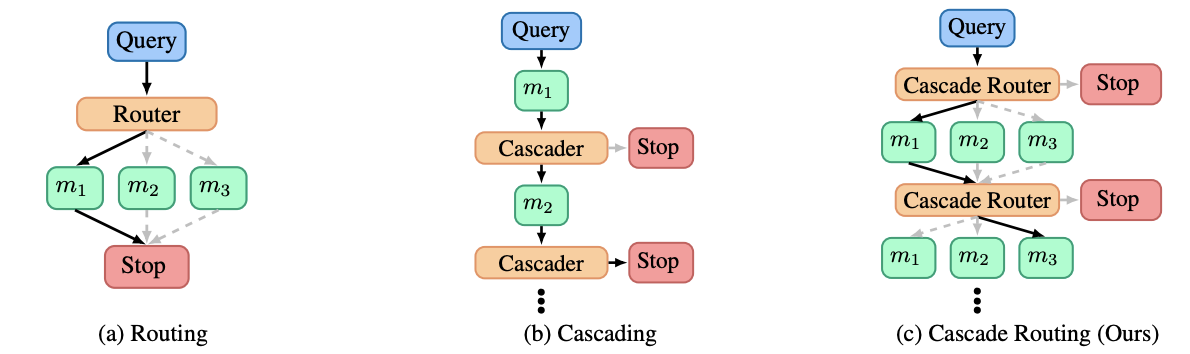
Cascading routers
Decompose and Reassemble
This advanced approach uses a more powerful LLM to break down the user’s query into many, far simpler tasks. Then those tasks can be answered by smaller LLMs, either local or cloud-based, often in parallel. Then, a final remote call merges all the responses together (similar to MapReduce). While not exactly routing like the other techniques, this approach similarly makes use of a variety of models (likely smaller and more specialized) to accomplish the job.
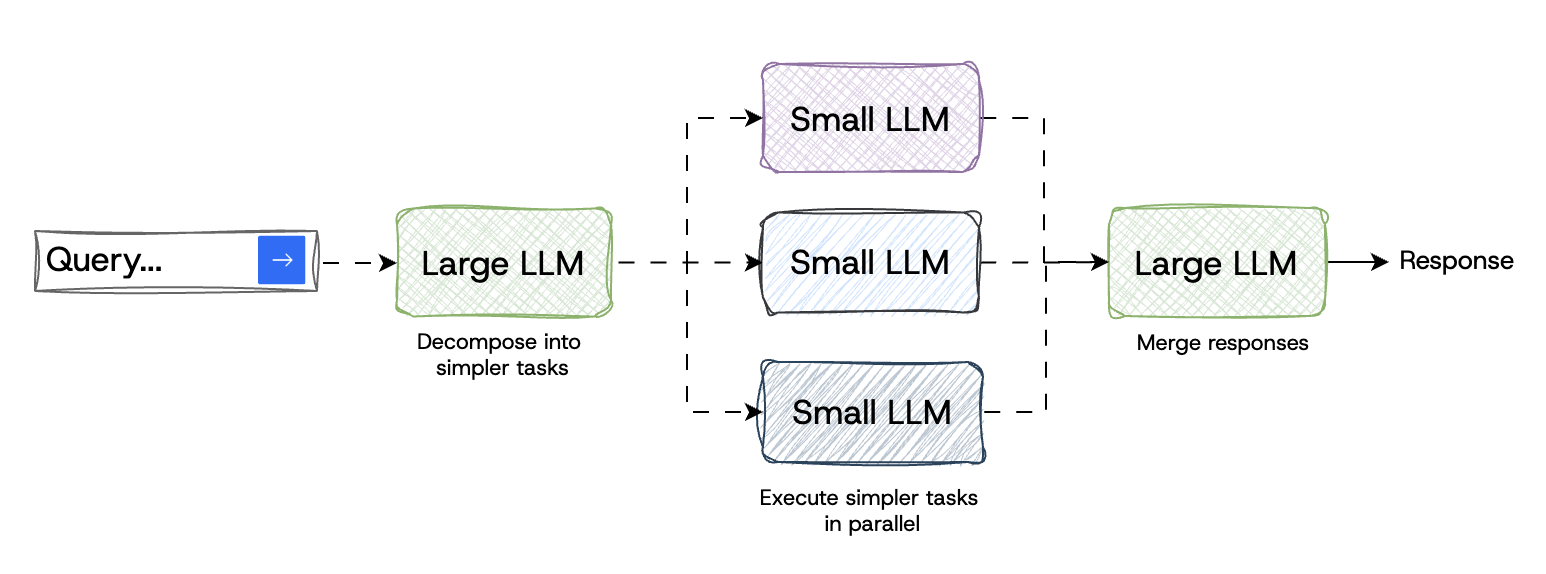
Use more powerful model to break down tasks and route to those
The MinionS Protocol shows this approach achieves 5.7x reduction in remote costs, while maintaining 97.9% of cloud model performance.
How to Build a Router
In all our examples, we assumed there was an existing router that “just works” and sends your query to the right place. But how do you build that?
The process begins with data preparation, where a diverse set of user queries is collected and labeled according to the performance of different LLMs in addressing them. For example, queries can be rated on a scale from 1 to 5, indicating how effectively a particular model responds. This labeled dataset serves as the foundation for training a classifier, such as a causal LLM, to predict which model is best suited for a given query. Fine-tuning a classifier involves training it on this labeled data to enhance its ability to accurately route queries.
Techniques like Low-Rank Adaptation (LoRA) can be employed to efficiently fine-tune your model. After training, the router’s performance is evaluated using benchmark datasets to ensure it effectively balances response quality and cost by directing queries to the appropriate LLMs.
The team behind one of the earliest LLM routers, trained four routers using Chatbot Arena data:
- A similarity-weighted (SW) ranking router that performs a “weighted Elo calculation” based on similarity
- A matrix factorization model that learns a scoring function for how well a model can answer a prompt
- A BERT classifier that predicts which model can provide a better response
- A causal LLM classifier that also predicts which model can provide a better response
Connection with Mixture of Experts
Mixture of Experts (MoE) is a model architecture where one large language model contains multiple specialized sub-models, known as “experts.” The roots come from the 1991 paper Adaptive Mixture of Local Experts, where only a subset of parameters are active in a neural net. It was designed to retain the best quality of an output while improving the overall efficiency and scalability. So, in essence an MoE model is performing routing to generate output tokens within the model itself as compared to routing across very different models.
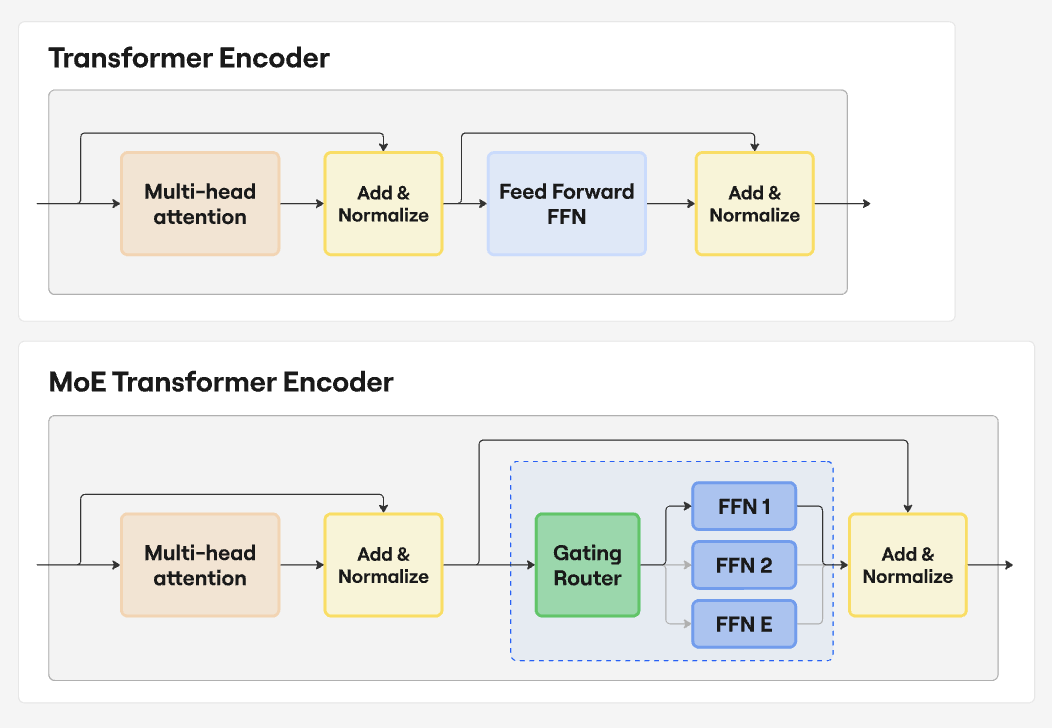
Traditional vs. Mixture of Experts model architecture
So while LLM routing chooses the best model for a task, MoE models have a gating network that selects the best “expert” for a given input token.
Conclusion
AGI may one day be the “master of all trades.” Today isn’t that day. And that’s fine. The winning pattern right now is a team of specialists with a great dispatcher. LLM routing is that dispatcher. It turns a messy, fast-changing model landscape into a system that is cheaper, faster, and just as accurate.
And because new models land weekly, a router isn’t just an optimization—it’s how you stay current without rewiring your product every month.
There also isn’t one “right” router. You can keep it simple (small vs. large), get smart with specialist routing, go hybrid with local models for easy wins, cascade when confidence drops, or decompose big problems and reassemble the answers. Mix and match. Let data, budget, and latency targets decide.
You May Also Enjoy

Is Ralph Wiggum the Future of Coding?Autonomous AI coding doesn't fail because models aren't smart enough. It fails because we give them too much context, vague g... |
The Next AI Breakthrough Is Old-Fashioned Software EngineeringThe next AI breakthrough won't be smarter models but reliable ones. Like self-driving cars, progress of AI agents means consi... |