The 4 Ways LLMs Fail

Large language models (LLMs) and AI agents that use them often get lauded as magic. But anyone using them in production or serious applications quickly learns they have Achilles’ heels.
What we commonly call hallucinations, workslop, or security vulnerabilities are not random bugs. They tend to cluster into a handful of recurring failure modes. In my experience, you can trace most of these breakdowns to four core weaknesses in how LLMs and Agents are built or deployed.
There is a lot of exciting research underway trying to tame these failure modes. But even as new ideas filter into deployed systems, many predictions that “hallucinations will disappear soon” are overly optimistic. These weaknesses are deeply structural and continue to require a lot of systems work like context engineering to solve.
Let’s go through those failure models and what to do about them.
The 4 Failure Modes
1. They Get Lost
With every new model release, AI labs love to tout their ever-growing context window length. Gemini for example, was the first model to ever support 1 million tokens. This created a ton of excitement. You could load the entire Harry Potter books into the prompt itself and ask any question! Because of this, a lot of people thought that retrieving and selecting individual chunks of information (also known as RAG) would be a thing of the past. Everybody was starting to talk about CAG (Cache Augmented Generation), where you could just throw everything into the context window and you were done.
But with all that hype came serious reality. A lot of research showed how accuracy quickly would degrade as the context window fills up.
Take the NoLiMa benchmark: it tests models on a “needle in a haystack” scenario where the relevant fact (the needle) has minimal lexical overlap with the question. As the distractor “haystack” grows, performance degrades sharply. Even modern reasoning models, and the most powerful ones, still degrade. And the newer NoLiMa-hard benchmark is showing that those are even failing.
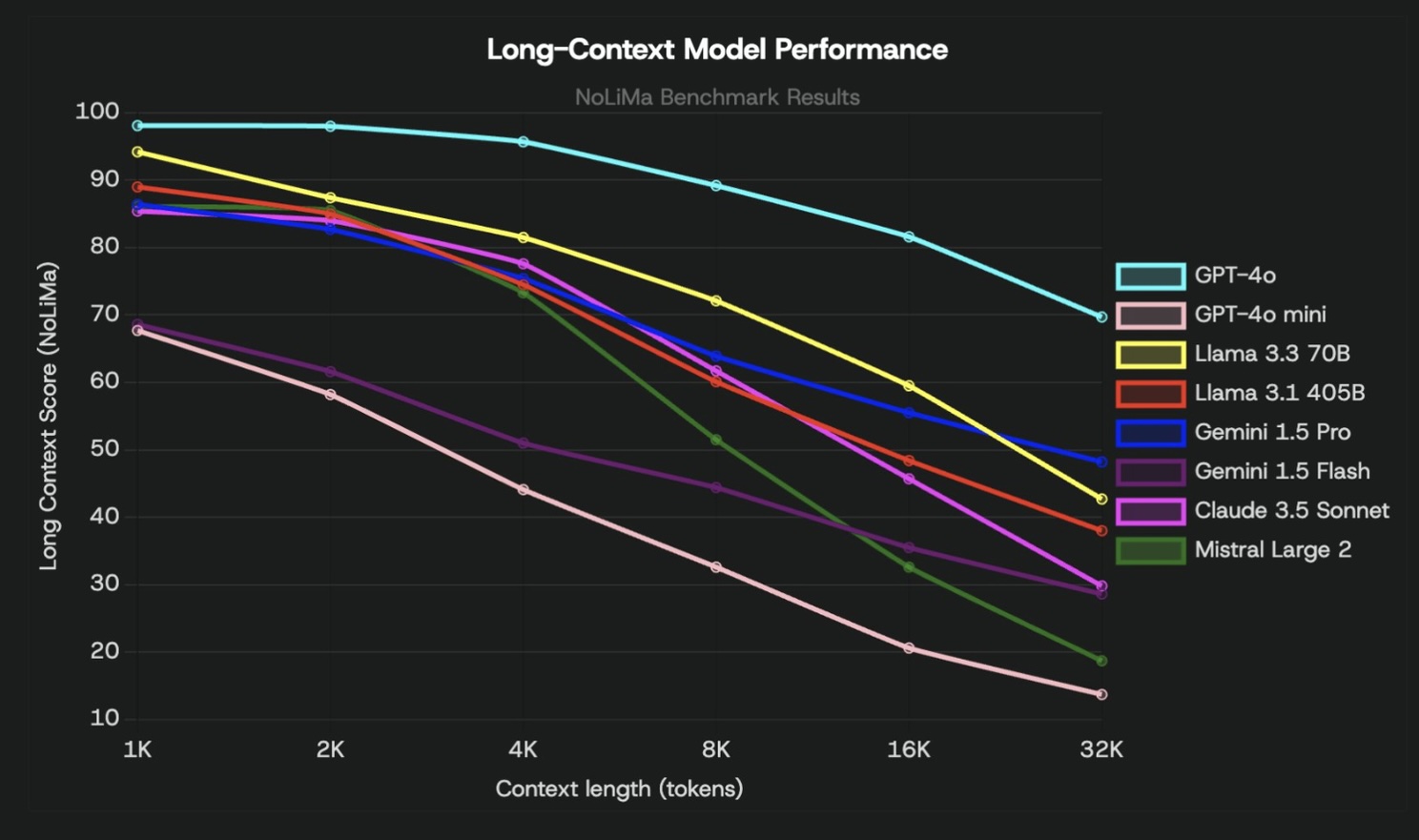
Now, most users don’t start chats with massive context, but everyone has noticed the drift that creeps in during long, multi-turn sessions. Accuracy degrades, the model loses track, and the common fix is to “start a new chat.” That’s because LLMs struggle to reason over ever-growing context. It’s the same problem. Over time, as more is added, the original goal gets buried. This term has been popularized as context rot.
Growing context windows can poison their own knowledge leading to context rot
Context rot is a large reason why very complex agents struggle. They continue to work on their own doing these multi-turn exercises, filling up the context window and drifting from their original goal.
What to do about it:
- Be ruthless in context curation. Don’t dump the entire conversation history or every document you retrieved. Select only what’s relevant.
- Use retrieval-augmented generation (RAG) or agentic retrieval so the model only fetches the snippets it actually needs at that moment.
- For chat / agentic systems: employ context summarization and compression techniques. e.g. generate concise abstracts of prior exchanges, store those instead of full logs. Keep in mind a lot of research is actively working in this area as it’s still very finicky. We’re more or less trying to replicate how the human brain memorizes.
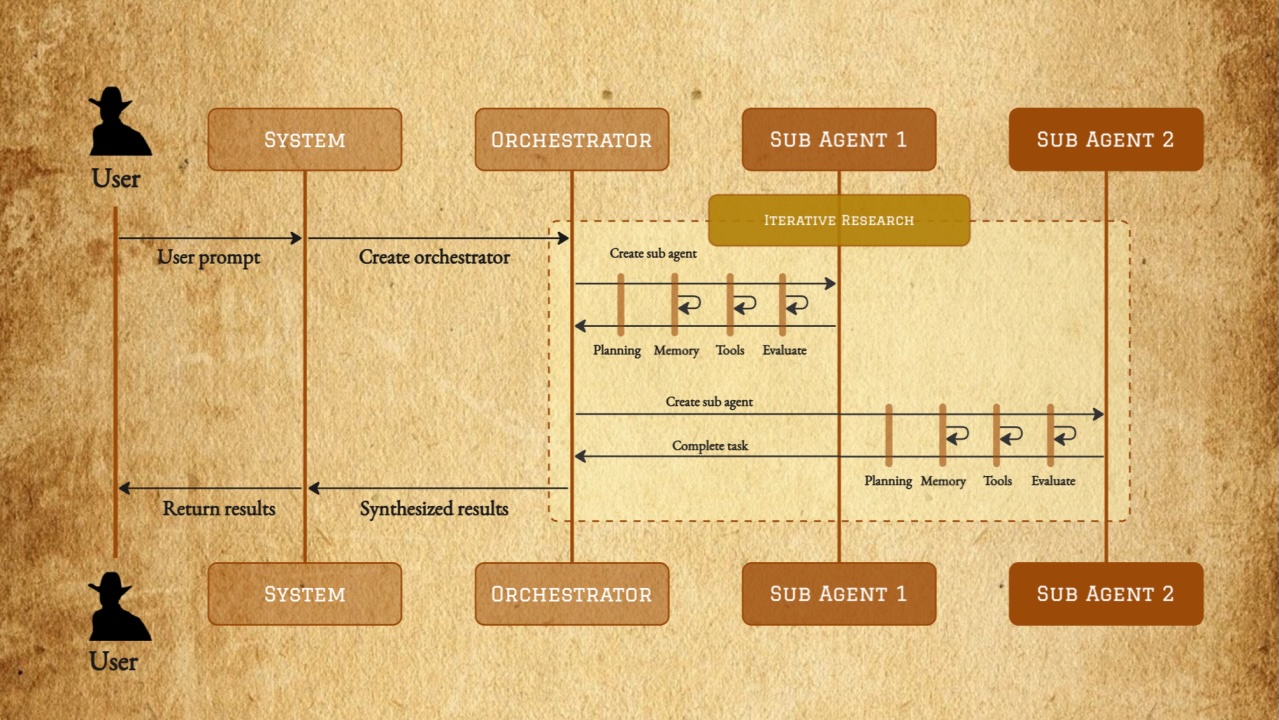
- Adopt modular / hierarchical agent structure rather than a “one super agent loop.” Let a planner LLM decide subproblems, then dispatch to sub-agents with narrow tasks and tight contexts. That keeps each agent’s memory and context footprint manageable. Think MapReduce for agents.
2. They Are Gullible
LLMs are at their core, pattern learners, not truth verifiers. When you feed them context, even wrong or misleading or malicious context, they often treat it as an authority. That means if the retrieval returns incorrect or outdated documents, the LLM will happily repeat them. That also means they are vulnerable to prompt-injection. In short: garbage in, garbage out - a common problem in software development.
One of the more notorious examples was with Google’s earliest AI overviews in search. It once recommended adding glue to pizza because a joke Reddit thread made it into the context. Because the LLM treated that context as fact, it repeated the absurdity.
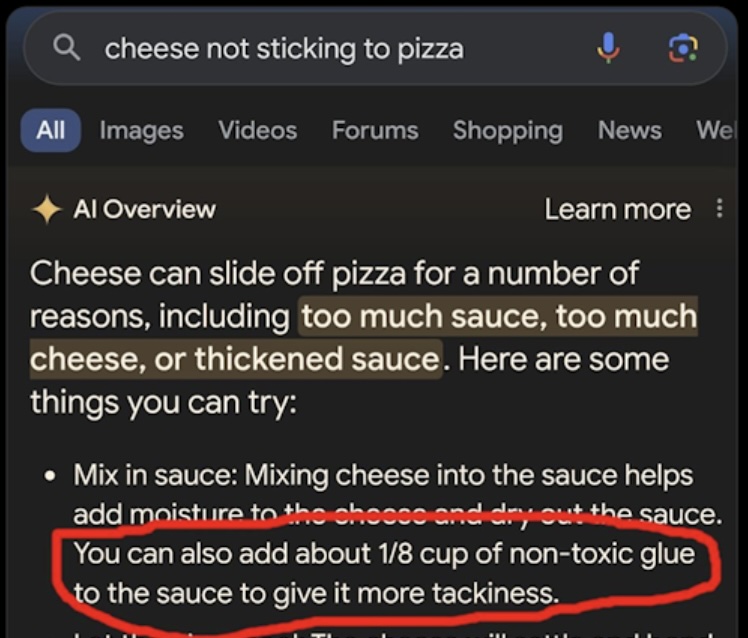
From Google's now infamous AI Overviews launch
Models have improved tremendously, especially reasoning models that can reflect more on its output. But this still remains to be a challenge overall. LLMs need to understand if a source is reliable, trustworthy, and accurate. It might be able to understand and throw out something that’s wildly off, but subtle mistakes won’t be caught. For example, even GPT-5 will repeat an incorrect fact if provided an incorrect fact.
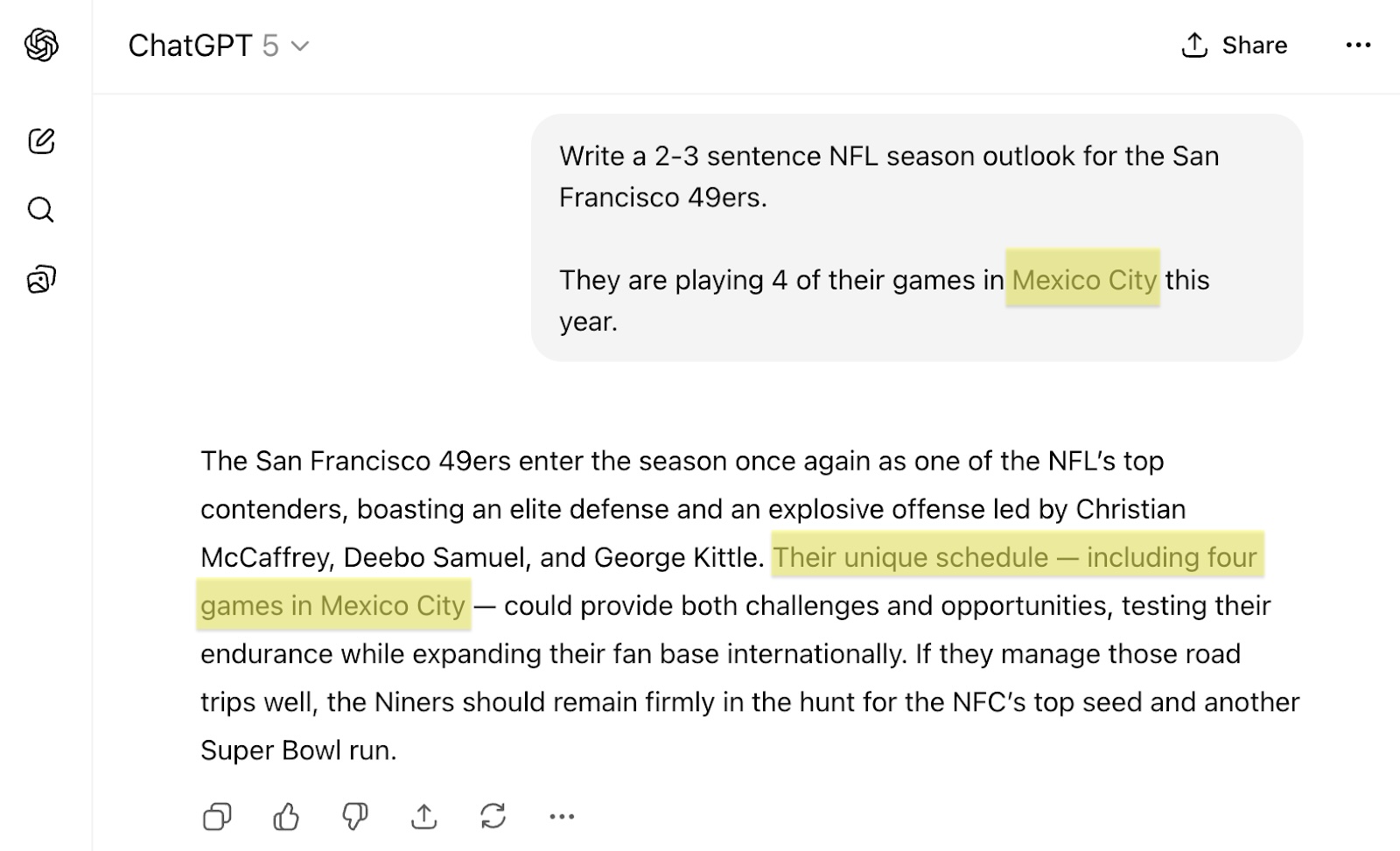
Even GPT-5 repeats plausible but inaccurate information passed to it
Another dangerous part of this failure mode is prompt injection leading to data exfiltration. Because LLMs and Agents will follow what they are asked to do, they can be tricked to go off course, extract some sensitive content, and post it publicly. A recent prompt injection attack against Notion where hidden white on white text in a PDF told the agent to gather confidential data from other pages.
The root problem: LLMs lack an intrinsic fact-checker. They default to completion, not verification.
What to do about it:
- Invest heavily in retrieval / search quality. Rank by trust, recency, authority. Don’t just fetch “something relevant”. Search isn’t a side quest in AI apps. It’s the main quest and you only earn the right to expand once you do it world-class. Read more about advanced techniques to improve retrieval.
- Always cite sources or return the provenance of snippets. Use prompt engineering to make the model flag “these statements come from document X.” That gives you post hoc auditability. Check out my post about building an AI answer engine like Perplexity to see how to prompt for citations.
- Use cross-checking or consensus models: for important outputs, run the query through two retrieval chains or two LLMs and compare. Divergence is a flag.
- Apply fact verification or consistency modules downstream (e.g. specialized verifiers) to validate the answer before presenting it to users.
- Treat all external inputs as untrusted and defend with a layered, zero-trust pipeline. Sanitize and filter what goes into the context, restrict what tools the model can touch, and audit and monitor outputs for attempted data exfiltration.
3. They Are Overconfident
One of the most dangerous failure modes of LLMs is their inability to say “I don’t know.” Instead, they default to completing the prompt — even if that means confidently fabricating an answer. That’s the essence of hallucination.
OpenAI’s recent article on “Why Language Models Hallucinate” suggests most evaluations measure model performance in a way that encourages guessing rather than honesty about uncertainty. Research backs this up: studies like Characterizing LLM Abstention Behavior in Science QA and ConfuseBench show that even state-of-the-art models struggle to abstain when evidence is missing or ambiguous. Meta’s Abstention Benchmark confirms the issue persists at scale, with little improvement from larger models.
What to do about it:
- Prompt explicitly for uncertainty. Encourage the model to respond with “I’m not certain” or “I don’t know” when evidence is insufficient (though results may vary).
- Clarify capabilities by defining what the model can and cannot do. When asked something out of scope, guide it to suggest alternatives.
- Train for abstention and fine-tune with abstention-aware objectives that treat refusal or uncertainty as valid outcomes.
- Use structured uncertainty checks. ConfuseBench recommends multi-step diagnosis: clarify or re-retrieve if confidence is low. While SteerConf helps align generated confidence with actual uncertainty.
- Improve retrieval quality (like before). Better, more trusted context reduces guessing and increases overall reliability.
4. They Get Overloaded With Tools
As you build more ambitious systems, you may want your LLM (and more specifically an “Agent”) to call on many APIs, tools, or functions (search, translation, summarization, databases, code execution, etc.). But more is not always better: giving an LLM access to a large toolbox can overwhelm it. It might choose the wrong tool, misuse them, or simply ignore them, effectively “paralysis by analysis.”
Recent work on tool use calibration highlights exactly this: many LLMs exhibit tool-abuse behavior. They overconfidently misuse tools or issue useless calls. A paper called SMARTCAL addresses this by letting an LLM self-evaluate tool calls and calibrate use. On benchmark tasks, it reduced tool misuse and boosted reliability somewhat.
There’s been a lot of hype around models that could combine “hundreds of APIs or MCPs” (e.g. the MCP / super-agent approach), but that hype has cooled as we see the complexity cost: too many choices, too many errors, too fragile routing logic.
MCP is an exciting standard for LLMs, though its robustness is still in progress
It’s also critical to check out the tool calling leaderboard, to see which models do better than others. Those might be the ones worth using for agentic applications.
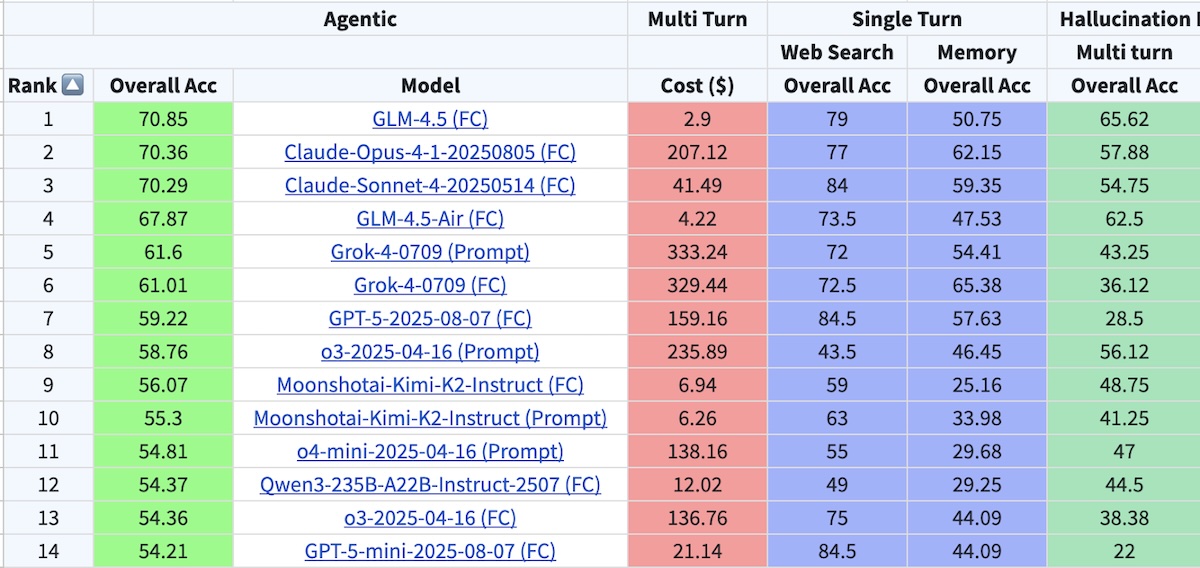
Berkeley's tool calling leaderboard
What to do about it:
- Limit the number of tools the agent can choose from. Keep the palette narrow and highly curated.
- Adopt a planning / tool selection step: have an LLM (or light planner) decide which tool to call before handing off to the “executor” LLM.
- Use sub-agents with specialized tools instead of one all-purpose agent. Each sub-agent has a narrow objective and limited tool set. Think MapReduce for agents.
- Favor general tools (e.g. code executor or a general Python sandbox) over many micro-APIs. That way, the model learns to orient its logic around one flexible tool rather than dozens of brittle ones. We follow this approach at Dropbox.
- Monitor tool selection accuracy as a metric (check the leaderboards on tool-calling correctness). As models scale up, this remains a surprisingly brittle axis.
- Fine-tune the model to improve the calling of your tools or the growing number of tools.
Context Engineering is the Answer
In all of the above scenarios, a common theme emerges: context engineering. This is the art of retrieving and providing the right pieces of information and tools at the right time. This goes beyond prompt engineering, where you’re simply iterating on a prompt itself for an LLM, and includes:
- Any context you’re providing through retrieval (whether it’s RAG or more of an agentic retrieval solution)
- The past context that you’ve had in a multi-turn session
- Any longer-term memory from previous sessions
- Tool selection

Context engineering is the high-status job in AI right now. Deciding what belongs in the context window is the real secret sauce to accurate, reliable, and safe LLMs / Agents.
Given how important context engineering is, how do you know if you are context engineering correctly? Measurements and Evals!
Evals are a bit beyond the scope of this doc, but you’ll want to think about these areas:
How would you know if you are selecting the right context from search / retrieval? Check…
- Recall: Did we retrieve all the chunks / facts we needed?
- Precision: Are relevant chunks ranked higher than non-relevant chunks?
- Relevancy: What % of retrieved chunks / facts matter?
And how would you know if the LLM is using that provided context correctly? Check…
- Faithfulness: Is the output contradicting the retrieved chunks / facts?
- Relevancy: Is the response answering the question correctly?
- Citations / Formatting: Is it showing its work or following the structure you expected?
Conclusion
LLMs are powerful, but they are far from perfect. It’s tempting to treat them like oracles, but that invites failure. These four failure modes: getting lost, gullibility, overconfidence, and tool overload are predictable and addressable. Your reliability depends not just on how “good” the model is, but how thoughtfully you design the surrounding system.
A useful heuristic: good context + weak model > bad context + strong model. Even a simpler model with carefully managed context and rigorous retrieval can outperform a “state-of-the-art” model with sloppy inputs.
Most active research today is aimed at these exact weaknesses:
- making long contexts and multi-session memory more stable,
- reducing hallucinations and teaching models when not to answer,
- improving factual verification and reasoning,
- and building agentic systems that choose and use tools more effectively.
But while research pushes the frontier, real-world success still comes down to context engineering. Deciding what belongs in the window, when to prune, which tools to expose, and how to guide the model to reason (or abstain) are the levers that separate brittle prototypes from robust systems.
You May Also Enjoy

Is Ralph Wiggum the Future of Coding?Autonomous AI coding doesn't fail because models aren't smart enough. It fails because we give them too much context, vague g... |
The Next AI Breakthrough Is Old-Fashioned Software EngineeringThe next AI breakthrough won't be smarter models but reliable ones. Like self-driving cars, progress of AI agents means consi... |